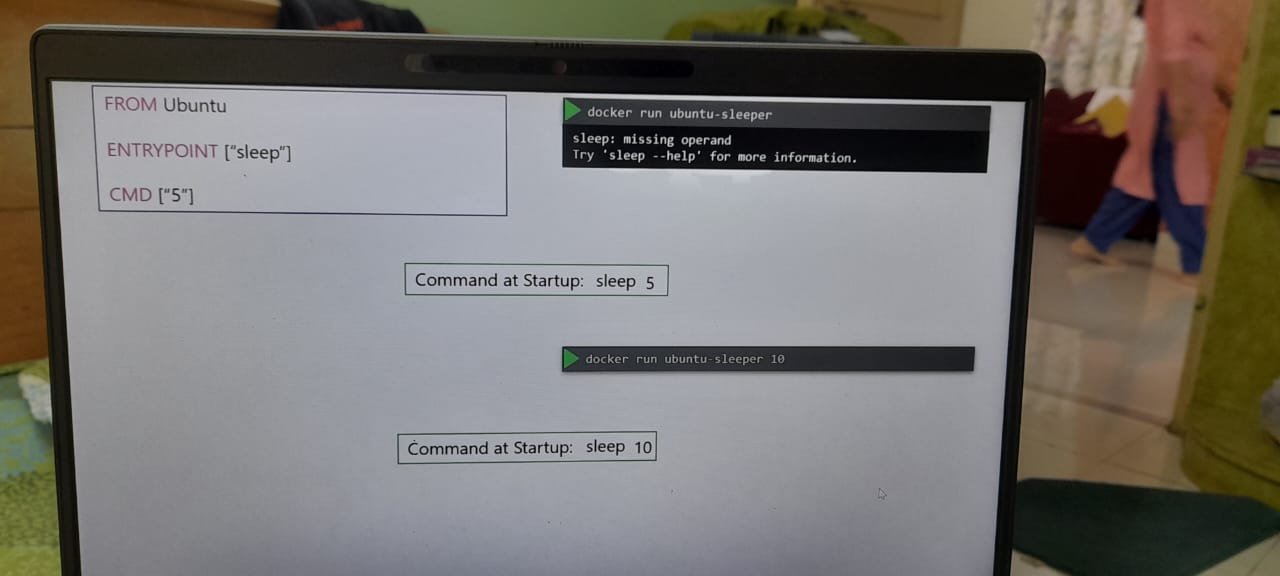
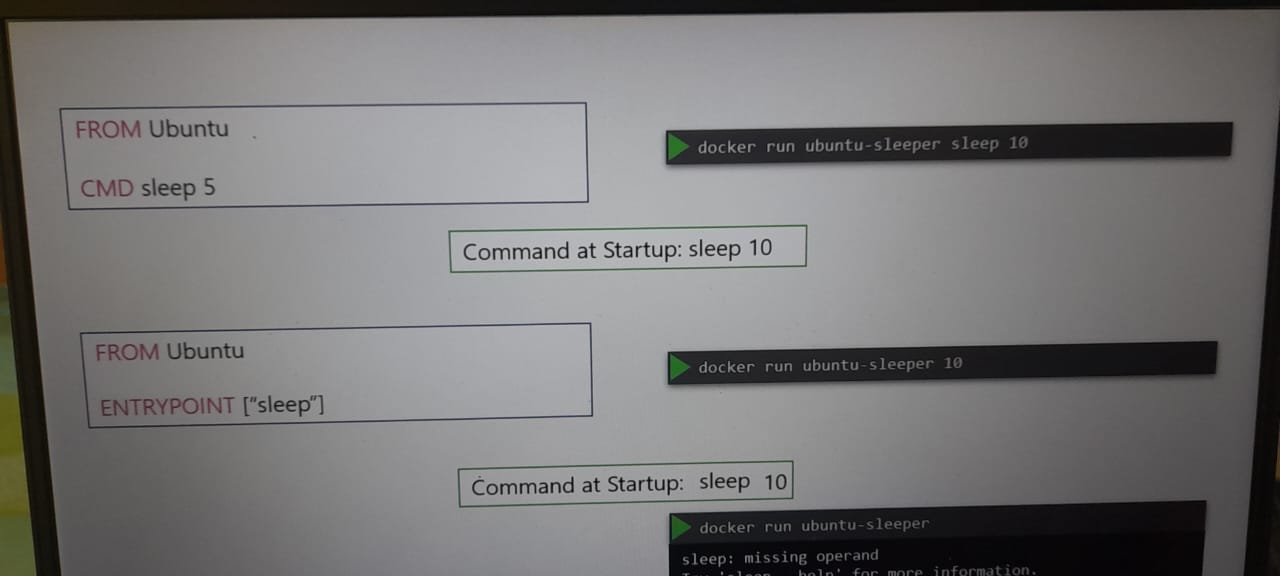
Registration request
https://www.sharetechnote.com/html/5G/5G_Registration.html#Case_A_NormalRegistration
PDF : https://www.eventhelix.com/5G/standalone-access-registration/details/5g-standalone-access-registration.pdf
PDF : https://www.eventhelix.com/5G/standalone-access-registration/5g-standalone-access-registration.pdf
Spec Details : https://www.sharetechnote.com/html/5G/5G_RadioProtocolStackArchitecture.html
RedCap : https://www.sharetechnote.com/html/5G/Handbook_5G_Index.html
5G Index for Share Note : https://www.sharetechnote.com/html/5G/Handbook_5G_Index.html
NGAP Message
NG Application Protocol (InitialUEMessage)
NGAP-PDU: initiatingMessage (0)
initiatingMessage
procedureCode: id-InitialUEMessage (15)
criticality: ignore (1)
value
InitialUEMessage
protocolIEs: 5 items
Item 0: id-RAN-UE-NGAP-ID
ProtocolIE-Field
id: id-RAN-UE-NGAP-ID (85)
criticality: reject (0)
value
RAN-UE-NGAP-ID: 2768240640
Item 1: id-NAS-PDU
ProtocolIE-Field
id: id-NAS-PDU (38)
criticality: reject (0)
value
NAS-PDU: 7e004179000d0164f0110fff000000000000102e04f0f0e0e02b0100
Non-Access-Stratum 5GS (NAS)PDU
Plain NAS 5GS Message
Extended protocol discriminator: 5G mobility management messages (126)
0000 .... = Spare Half Octet: 0
.... 0000 = Security header type: Plain NAS message, not security protected (0)
Message type: Registration request (0x41) <-- Type of message ( If NAS_5GS_MSG_REGISTRATION_REQ then TMSI allocation is done
5GS registration type
.... 1... = Follow-On Request bit (FOR): Follow-on request pending
.... .001 = 5GS registration type: initial registration (1)
NAS key set identifier
0... .... = Type of security context flag (TSC): Native security context (for KSIAMF)
.111 .... = NAS key set identifier: 7
5GS mobile identity
Length: 13
0... .... = Spare: 0
.000 .... = SUPI format: IMSI (0)
.... 0... = Spare: 0
.... .001 = Type of identity: SUCI (1)
Mobile Country Code (MCC): China (460)
Mobile Network Code (MNC): Unknown (11)
Routing indicator: ?0
.... 0000 = Protection scheme Id: NULL scheme (0)
Home network public key identifier: 0
MSIN: 0000000001
UE security capability
Element ID: 0x2e
Length: 4
1... .... = 5G-EA0: Supported
.1.. .... = 128-5G-EA1: Supported
..1. .... = 128-5G-EA2: Supported
...1 .... = 128-5G-EA3: Supported
.... 0... = 5G-EA4: Not supported
.... .0.. = 5G-EA5: Not supported
.... ..0. = 5G-EA6: Not supported
.... ...0 = 5G-EA7: Not supported
1... .... = 5G-IA0: Supported
.1.. .... = 128-5G-IA1: Supported
..1. .... = 128-5G-IA2: Supported
...1 .... = 128-5G-IA3: Supported
.... 0... = 5G-IA4: Not supported
.... .0.. = 5G-IA5: Not supported
.... ..0. = 5G-IA6: Not supported
.... ...0 = 5G-IA7: Not supported
1... .... = EEA0: Supported
.1.. .... = 128-EEA1: Supported
..1. .... = 128-EEA2: Supported
...0 .... = 128-EEA3: Not supported
.... 0... = EEA4: Not supported
.... .0.. = EEA5: Not supported
.... ..0. = EEA6: Not supported
.... ...0 = EEA7: Not supported
1... .... = EIA0: Supported
.1.. .... = 128-EIA1: Supported
..1. .... = 128-EIA2: Supported
...0 .... = 128-EIA3: Not supported
.... 0... = EIA4: Not supported
.... .0.. = EIA5: Not supported
.... ..0. = EIA6: Not supported
.... ...0 = EIA7: Not supported
UE status
Element ID: 0x2b
Length: 1
0... .... = Spare: 0
.0.. .... = Spare: 0
..0. .... = Spare: 0
...0 .... = Spare: 0
.... 0... = Spare: 0
.... .0.. = Spare: 0
.... ..0. = N1 mode reg: UE is not in 5GMM-REGISTERED state
.... ...0 = S1 mode reg: UE is not in EMM-REGISTERED state
Item 2: id-UserLocationInformation
ProtocolIE-Field
id: id-UserLocationInformation (121)
criticality: reject (0)
value
UserLocationInformation: userLocationInformationNR (1)
userLocationInformationNR
nR-CGI
pLMNIdentity: 64f011
Mobile Country Code (MCC): China (460)
Mobile Network Code (MNC): Unknown (11)
0000 0000 0000 0000 0000 0000 0000 0000 0001 .... = nRCellIdentity: 0x000000001
tAI
pLMNIdentity: 64f011
Mobile Country Code (MCC): China (460)
Mobile Network Code (MNC): Unknown (11)
tAC: 136 (0x000088)
Item 3: id-RRCEstablishmentCause
ProtocolIE-Field
id: id-RRCEstablishmentCause (90)
criticality: ignore (1)
value
RRCEstablishmentCause: mo-Signalling (3)
Item 4: id-UEContextRequest
ProtocolIE-Field
id: id-UEContextRequest (112)
criticality: ignore (1)
value
UEContextRequest: requested (0)
Details
- Registration is first procedure that UE executes after being switched on.
When is it performed?
Initial registration
UE to connect to network after Power ON
Periodic Registration
Used by UEs in CM-IDLE mode
Mobility registration
When UE moves out of registration area
Emergency Registration
Used by UE when it wants to register only for emergency services.
Sequence Diagram
Allocate TMSI-AmfUeNgapId
Input : Message type: Registration request (0x41)
If Message type: Registration request (0x41) then allocate TMSI for NGAP -id
PCAP:
297 47.530339 HTTP2 10.233.102.158 43564 10.233.102.134 8082 Magic, SETTINGS[0], WINDOW_UPDATE[0], HEADERS[1]: POST /amf-ueidgen/v1/allocate/tmsi-amfuengapid, DATA[1]
Response :
amf_ue_ngap_id
newly_allocated_tmsi
Insert Stickiness
Discover AUSF
- requester-nf-type
- target-nf-type
- requester-plmn-list
- target-plmn-list
337 47.556192 HTTP2 10.233.102.158 47684 10.233.102.136 8082 Magic, SETTINGS[0], WINDOW_UPDATE[0], HEADERS[1]: GET /nnrf-disc/v1/nf-instances?requester-nf-type=AMF&service-names=nausf-auth&target-nf-type=AUSF&target-plmn-list=%5B%7B%22mcc%22:%22460%22,%22mnc%22:%2211%22%7D%5D&requester-plmn-list=%5B%7B%22mcc%22:%22460%22,%22mnc%22:%2211%22%7D%5D&routing-indicator=0, DATA[1]
AUSF Interaction
1. AMF -> AUSF
379 47.577265 HTTP2/JSON 10.233.102.158 39124 10.233.102.151 8082 Magic, SETTINGS[0], WINDOW_UPDATE[0], HEADERS[1]: POST /nausf-auth/v1/ue-authentications, DATA[1], JSON (application/json)
{
"servingNetworkName": "5G:mnc011.mcc460.3gppnetwork.org",
"supiOrSuci": "suci-0-460-11-0-0-0-0000000001"
}
2. AUSF -> NRF to search UDM
395 47.582120 HTTP2 10.233.102.151 50558 10.233.102.136 8082 Magic, SETTINGS[0], WINDOW_UPDATE[0], HEADERS[1]: GET /nnrf-disc/v1/nf-instances?requester-nf-type=AUSF&service-names=nudm-ueau&target-nf-type=UDM&target-plmn-list=%5B%7B%22mcc%22:%22460%22,%22mnc%22:%2211%22%7D%5D&routing-indicator=0, DATA[1]
3. Generate Auth Data
423 47.596608 HTTP2/JSON 10.233.102.151 41954 10.233.102.186 8082 Magic, SETTINGS[0], WINDOW_UPDATE[0], HEADERS[1]: POST /nudm-ueau/v1/suci-0-460-11-0-0-0-0000000001/security-information/generate-auth-data, DATA[1], JSON (application/json)
4. Response ( UDM -> AUSF )
439 47.607821 HTTP2/JSON 10.233.102.186 8082 10.233.102.151 41954 HEADERS[1]: 200 OK, DATA[1], JSON (application/json)
{
"authType": "5G_AKA",
"authenticationVector": {
"autn": "1eef1979cf8880000b1213b397c4fa6e",
"avType": "5G_HE_AKA",
"kausf": "8b18d5cc67cab8dacb6d9508e7c55a5ff9534851c2b672241fed0222d1b8a91f",
"rand": "48422b0173dac70601a7639e8fa3f021",
"xresStar": "407e46fc8df09518a2047ed2073f2745"
},
"supi": "imsi-460110000000001"
}
5. ( AUSF -> AMF )
447 47.620055 HTTP2/JSON 10.233.102.151 8082 10.233.102.158 39124 HEADERS[1]: 201 Created, DATA[1], JSON (application/3gpphal+json)
{
"5gAuthData": {
"autn": "1eef1979cf8880000b1213b397c4fa6e",
"hxresStar": "6cd18a485e84c7dbecb85fdeb1e40d4f",
"rand": "48422b0173dac70601a7639e8fa3f021"
},
"_links": {
"5g-aka": {
"href": "http://ausf-auth.radisys-ausf1:8082/nausf-auth/v1/ue_authentications/suci-0-460-11-0-0-0-0000000001"
}
},
"authType": "5G_AKA",
"servingNetworkName": "5G:mnc011.mcc460.3gppnetwork.org"
}
AMF -> UE ( Authentication Request )
451 47.626693 NGAP/NAS-5GS 10.233.102.150 172.27.29.125 SACK (Ack=1, Arwnd=212992) , DownlinkNASTransport, Authentication request
NGAP-PDU: initiatingMessage (0)
initiatingMessage
procedureCode: id-DownlinkNASTransport (4)
criticality: ignore (1)
value
DownlinkNASTransport
protocolIEs: 3 items
Item 0: id-AMF-UE-NGAP-ID
ProtocolIE-Field
id: id-AMF-UE-NGAP-ID (10)
criticality: reject (0)
value
AMF-UE-NGAP-ID: 2021
Item 1: id-RAN-UE-NGAP-ID
ProtocolIE-Field
id: id-RAN-UE-NGAP-ID (85)
criticality: reject (0)
value
RAN-UE-NGAP-ID: 2768240640
Item 2: id-NAS-PDU
ProtocolIE-Field
id: id-NAS-PDU (38)
criticality: reject (0)
value
NAS-PDU: 7e0056000200002148422b0173dac70601a7639e8fa3f02120101eef1979cf8880000b1213b397c4fa6e
Non-Access-Stratum 5GS (NAS)PDU
Plain NAS 5GS Message
Extended protocol discriminator: 5G mobility management messages (126)
0000 .... = Spare Half Octet: 0
.... 0000 = Security header type: Plain NAS message, not security protected (0)
Message type: Authentication request (0x56)
0000 .... = Spare Half Octet: 0
NAS key set identifier - ngKSI
.... 0... = Type of security context flag (TSC): Native security context (for KSIAMF)
.... .000 = NAS key set identifier: 0
ABBA
Length: 2
ABBA Contents: 0000
Authentication Parameter RAND - 5G authentication challenge
Element ID: 0x21
RAND value: 48422b0173dac70601a7639e8fa3f021
Authentication Parameter AUTN (UMTS and EPS authentication challenge) - 5G authentication challenge
Element ID: 0x20
Length: 16
AUTN value: 1eef1979cf8880000b1213b397c4fa6e
SQN xor AK: 1eef1979cf88
AMF: 8000
MAC: 0b1213b397c4fa6e
UE -> AMF (Authentication Response)
NGAP-PDU: initiatingMessage (0)
initiatingMessage
procedureCode: id-UplinkNASTransport (46)
criticality: ignore (1)
value
UplinkNASTransport
protocolIEs: 4 items
Item 0: id-AMF-UE-NGAP-ID
ProtocolIE-Field
id: id-AMF-UE-NGAP-ID (10)
criticality: reject (0)
value
AMF-UE-NGAP-ID: 2021
Item 1: id-RAN-UE-NGAP-ID
ProtocolIE-Field
id: id-RAN-UE-NGAP-ID (85)
criticality: reject (0)
value
RAN-UE-NGAP-ID: 2768240640
Item 2: id-NAS-PDU
ProtocolIE-Field
id: id-NAS-PDU (38)
criticality: reject (0)
value
NAS-PDU: 7e00572d10407e46fc8df09518a2047ed2073f2745
Non-Access-Stratum 5GS (NAS)PDU
Plain NAS 5GS Message
Extended protocol discriminator: 5G mobility management messages (126)
0000 .... = Spare Half Octet: 0
.... 0000 = Security header type: Plain NAS message, not security protected (0)
Message type: Authentication response (0x57)
Authentication response parameter
Element ID: 0x2d
Length: 16
RES: 407e46fc8df09518a2047ed2073f2745 << Should match with "xresStar": "407e46fc8df09518a2047ed2073f2745"
Item 3: id-UserLocationInformation
ProtocolIE-Field
id: id-UserLocationInformation (121)
criticality: ignore (1)
value
UserLocationInformation: userLocationInformationNR (1)
userLocationInformationNR
nR-CGI
pLMNIdentity: 64f011
Mobile Country Code (MCC): China (460)
Mobile Network Code (MNC): Unknown (11)
0000 0000 0000 0000 0000 0000 0000 0000 0001 .... = nRCellIdentity: 0x000000001
tAI
pLMNIdentity: 64f011
Mobile Country Code (MCC): China (460)
Mobile Network Code (MNC): Unknown (11)
tAC: 136 (0x000088)